微服务架构下分布式事务模式详解及其在数据处理服务中的对比分析
随着微服务架构的普及,服务间的数据一致性成为关键挑战,尤其在数据处理服务这类对数据准确性要求极高的场景中。传统的单机数据库事务(ACID)难以直接跨越服务边界,因此,多种分布式事务模式应运而生。本文将详细对比几种主流模式,并探讨其在数据处理服务中的适用性。
1. 两阶段提交(2PC)
原理:引入一个协调者(Coordinator)来统一管理所有参与者(Participant)的事务提交。分为准备阶段(投票)和提交阶段(执行)。
优点:强一致性,保证所有服务同时成功或失败。
缺点:同步阻塞,性能低下;协调者单点故障风险;网络分区下可能长时间锁定资源。
数据处理服务适用场景:适用于对一致性要求极端严格、且事务参与方较少、性能非首要考虑的场景,如金融核心系统的账务处理。
2. 补偿事务(TCC)
原理:将事务拆分为Try(尝试)、Confirm(确认)、Cancel(取消)三个阶段。Try阶段预留资源,Confirm提交,Cancel回滚。
优点:最终一致性,性能较好,避免了长事务锁。
缺点:业务侵入性强,需为每个服务设计三个接口;实现复杂度高。
数据处理服务适用场景:适用于业务流程明确、可清晰划分“预留-确认”步骤的数据处理,如订单处理(扣库存、创建订单、扣优惠券)。
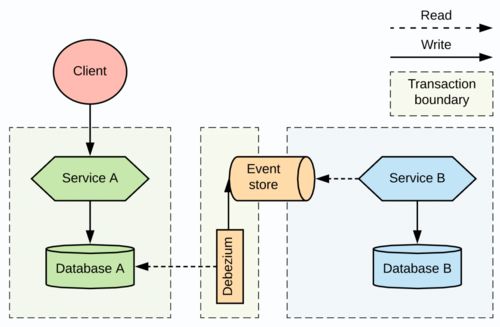
3. 基于消息的最终一致性(本地消息表、事务消息)
原理:利用消息队列作为事务协调媒介。生产者服务在本地事务中记录消息(或通过RocketMQ等支持的事务消息),消费者服务异步消费并处理,通过重试机制保证最终一致。
优点:解耦彻底,性能高,可用性好。
缺点:只保证最终一致性,存在延迟;消费者需实现幂等性。
数据处理服务适用场景:适用于高并发、允许短暂不一致的数据处理场景,如用户行为日志采集、统计报表生成、数据同步管道。
4. Saga模式
原理:将一个长事务拆分为一系列本地子事务,每个子事务都有对应的补偿操作。通过编排(Orchestration)或协同(Choreography)方式协调执行,失败时按逆序执行补偿。
优点:适合长业务流程,避免长时间锁定资源。
缺点:编程模型复杂;难以保证隔离性(可能出现脏读)。
数据处理服务适用场景:适用于跨多服务的复杂、长时间运行的数据处理流程,如电商的订单履约(下单、支付、发货、结算),或数据ETL(抽取、转换、加载)管道。
综合对比与选型建议
对于数据处理服务,选型需综合考虑数据一致性要求、性能、复杂度与业务特点:
- 强一致性优先:若处理的是核心财务、交易数据,可考虑2PC(但需承受性能代价)或结合业务特点的TCC。
- 高吞吐与最终一致性可接受:绝大多数数据加工、分析、异步处理场景,基于消息的最终一致性是首选,架构简单且扩展性强。
- 复杂长流程:涉及多步骤的数据处理工作流,Saga模式(尤其是编排式)能提供更好的可控性和可观测性。
在实践中,往往采用混合模式。例如,核心订单创建用TCC保证关键步骤一致性,后续的物流通知、积分更新等则通过消息队列异步处理。关键在于根据数据处理服务的具体子域(如实时计算、批处理、数据同步)和业务容忍度,选择最合适的模式,并在一致性、可用性与性能之间取得最佳平衡。
如若转载,请注明出处:http://www.bdanbao.com/product/76.html
更新时间:2026-06-19 22:45:37